A microservice architecture is a software development concept in which an application is broken down into small, independent, and loosely coupled services. In this architecture, the communication overall functionality is made through a well-defined protocol such as HTTP/REST or messaging systems and not through a centralized program as happens when using Monolithic Architecture.
The microservice architecture is commonly used to solve the usual problems involving large applications such as monolithic architecture. During this migration process, the organization may gradually start the transition of smaller and less critical services as this may be helpful for teams to get a solid understanding of the migration process and get hand of it. However, it is important to notice that the organization must have already carefully planned and taken under consideration the benefits and challenges ahead. It’s worth nothing migrating without a team which is able to grasp the complexity of handling distributed services.

A monolithic architecture is commonly chosen as the fastest approach for development and to get the business going. That architecture consolidates all components into a single application and it is frequently managed by multiple teams. However, the easiest may not be the simplest, as the code grows and gets more complex. As a result, large enterprises and startups tend to move towards a more agile architecture.
Uber: the challenge of managing two monolithic applications
When it comes to dealing with monoliths, Uber is undoubtedly a good example for this article.

Uber is a transportation company whose main product is an application that allows people to hail a ride through a smartphone. During its foundation time the company was providing services to a single city: San Francisco. In that time, the company was still getting space and didn’t have as many employees as it does now. So due to that, using a monolithic architecture was chosen as a well-suited approach to the role. But there was something that they hadn’t predicted: their growth.
Once the company became famous as a alternative to taxi cabs, it didn’t only grow in size and teams but also in code as well. Bringing new functionality as well as maintaining the code became extremely complicated. The most severe aspect regarded the large monolithic deployment because it required the entire application to be compiled, tested and supervised. Therefore, only experienced developers were allowed to deploy, obviously because if any component had an issue, that would compromise the entire application.
Finally, around 2012 up to 2013, the company was moving towards microservice architecture.
Microservices communication Types
A traditional monolithic architecture makes use of inter-process communication. This means that the communication is based on one process and makes calls to another programmatically. Therefore, there are no network problems in using this approach but the code is tightly coupled and hard do manage over time.
Contrary to Monolithic architecture, the microservice architecture is slightly different. As it is a distributed service, we are dealing with network protocols such as Rest or AMQP protocols. In this approach, the manner of waiting and dealing with request and response is important as we will see ahead.
Synchronous communication
This is a traditional form of communication. In this pattern a client sends a request and waits for a response from the server. Once the response is received, the client can continue to the next task. We call this operation a blocking operation as our application is dependent on an answer and it has to wait for it.
There are plenty of examples that can be given:
- When you make a search.
- When you calculate a shipping price using your zipcode.
- When you estimate the delivery time of a product to your home.
- When you navigate through a website page.
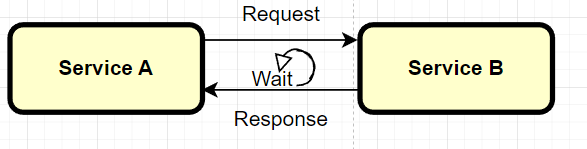
But it is important to notice that there are drawbacks when using this approach:
- Tightly couple: It is recommended that services follow the pattern of being independent, autonomous and isolated as much as possible. However, when using the synchronous strategy, the service has the knowledge about the service integration which creates undesirable ties. As a result, if there is the need of creating new services integrations or changes upon any way, we have to refactor our service in order to handle the new features.
- Client Error Handling: Communication problems may happen during the network exchange. In these cases, the application may need to have a fallback and retrieve the lost/outdated data.
- API Versioning: When an application provides a Rest endpoint, there is an interface contract that must be followed in order to request and send data. Making changes to these endpoints can lead to incompatibility between the services. To maintain compatibility, it may be necessary to introduce new changes or to create a new version of the endpoint. This way, old clients can continue using their endpoint version while new clients use the new endpoint version.
Asynchronous communication
Let’s suppose that you are in charge of creating a new feature which has to handle products operations like mass exclusion, price changing or stock update. That operation is the result of a seller managing their products through a marketplace website. To ensure that the application doesn’t get overwhelmed and unstable, you’ve chosen to delegate this bulk operation to a service. But there is a problem: how are you going to send the data to the service, and what type of communication do you need?

When talking about the synchronous operation, we notice that during it the client (which in this case is the application) has to wait for a response, right? In other words, we can’t use this approach as this may overload your application with blocking threads. And if we take under consideration the payload size, our main application may require additional processing resources, as multiple sellers can make a bulk action anytime. But well then, how can we send this data without having to wait for a response? We should sent it asynchronously, of course!
When it comes to asynchronous communication the strategy changes completely. In this pattern, the service which sends the data doesn’t wait for a response in order to proceed. To achieve this strategy, there is an intermediate who is in charge to receive messages and organize them like a queue. We say he is responsible to organize because this process is not limited to one service to another, now, multiple services can read from that queue and share the load among them. Furthermore we unlocked benefits such as scalability, autonomy, service loose coupling and last but not least: surges and spikes control.
As we can send as many message as we want, now we can deal with the payload size as well. We can send the message separately, which means that the sender (Or producer) doesn’t need to concentrate so many efforts at once to send the data. As a result, if we are going to process 5000 products, we can share the payload into small ones as many time as we want to prevent a resource spike. In this example, we can split the payload into 500 products per message, so, we are going to send 10 times to reach 5000.
Pros
- The service becomes both autonomous and loosely couple application.
- The service doesn’t has to reject request in case of being overwhelmed.
- The service has autonomy to consume the messages. And hardly will get overwhelmed.
- Allows multiples producers and consumers.
- In case of a service failure, the messages will remain safely in the queue.
Cons
- The operation takes time.
- Adds more complexity.
Benefits
1. Scalability and Flexibility
One difficulty when dealing with large applications is that, if any component require additional hardware resource, the entire application needs to be scaled up. As a result, this leads to more money and resources expending. But, In the other hand, when it comes to distributed services, as the application is separated into a small, well-defined and independent service, that problem is solved.
2. Technology Independence
Using this architecture, the application is not locked into a specific language, framework or technology. It can be developed independently by the time with its own technology and team.
3. Domain Control
A common problem from monolithic application is that due it is managed from multiple teams, parts of the code tend to be accessible unrestricted. When it comes to microservices the domain is a slightly restricted to the application. This in terms of security is extremely recommended and also prevent the code getting tightly-coupled.
4. Fault tolerant
Unlike monolithic applications, if any part of the application has a issue, it will not affect the whole application or result into crash.
Drawbacks
1. Inter-services and communication complexity
Microservices architectures often involve numerous interconnected services, each responsible for a specific functionality. Coordinating communication between these services can become complex, especially as the number of services and interactions increases.
2. Log and debug management
When working with multiple microservices, it can be difficult and challenging to manage debug and troubleshoot application logs. This is primarily because setting breakpoints and debugging the application can cause timeouts when one microservice was stopped by a debug breakpoint and was waiting for an answer. As a result, it becomes problematic to continue the debugging process. Although it is possible to configure the timeouts, it requires additional time and effort.
Conclusion
While a monolithic architecture is characterized by a single, tightly coupled application where all functionalities are bundled together, microservices architecture decomposes the system into smaller, loosely coupled services that communicate with each other, offering improved scalability, flexibility, and independent development. However, microservices bring complexity in terms of inter-service communication, deployment, and monitoring as we see in this article. Choosing between these two architectures depends on factors such as the size and complexity of the application, the development team’s expertise, scalability requirements, and the need for rapid iteration. Ultimately, the decision should align with the specific needs and goals of the project at hand.

Leave a comment